

ไฟล์ Robots.txt จะทำหน้าที่อนุญาตและยกเว้นการเข้าถึงไฟล์และโฟลเด้อต่าง ๆ ที่อยู่บน web server ให้กับ web robots ซึ่งเป็นโปรแกรมรวมรวมข้อมูลเว็บไซต์ ( Crawlers หรือบางทีเรียกว่า Spider ) ซึ่งถูกรันแบบอัตโนมัติจาก
หลากหลายแหล่งที่มา และเพื่อความเป็นส่วนตัวของข้อมูลบนโลกอินเตอร์เน๊ต ซึ่งอาจจะมีข้อมูลบางอย่างบนเว็บไซต์ที่เราไม่ต้องการให้ robots เหล่านี้นำไปทำ index หรือทำอย่างอื่น จึงเกิดไฟล์ robots.txt ขึ้นมาเพื่อบอกให้ robots เหล่านั้นรู้ว่า directory ส่วนไหน หรือไฟล์ไหนบนเว็บไซต์ของเรา ที่สามารถนำไปทำ index ได้และไฟล์ไหนไม่อนุญาตให้นำไปสร้าง index เมื่อ web robots เข้ามายังเว็บไซต์ของเรา จะทำการอ่านไฟล์ robots.txt และรับรู้ว่าส่วนไหนอนุญาตและไม่อนุญาต ก่อนที่จะไปเก็บข้อมูลหน้าเว็บไซต์ของเรา
สำหรับนักพัฒนาเว็บไซต์โดยทั่วไป เมื่อเราพัฒนาเว็บไซต์ให้ลูกค้าในขั้นตอนของการพัฒนา ( development ) ก่อนที่จะนำขึ้นใช้งานจริง ( production ) อาจจะต้องรักษาข้อมูลทั้งหมดในเว็บไซต์ให้เป็นความลับ เราอาจจะคิดว่าสร้างเว็บไซต์และเก็บไว้ใน sub directory คงไม่ใครรู้ ถ้าไม่ได้ส่งให้ใคร แต่ในความเป็นจริง Web Robots ได้เก็บข้อมูลเว็บไซต์ของเราไปแล้ว และถ้าเราลองพิมพ์คำสั่ง site:www.your-domain.com ใน addresss bar ของเว็บเบราว์เซอร์ จะเห็นว่ามีรายการเว็บไซต์ที่เป็นความลับอยู่ในลิสต์รายการด้วย
เราสามารถสร้างไฟล์ robots.txt โดยใช้โปรแกรม editor ทั่วไป และสามารถเขียนคำสั่งลงไปได้ แต่มีกฏอยู่ว่าไฟล์ต้องมีชื่อว่า robots.txt เท่านั้น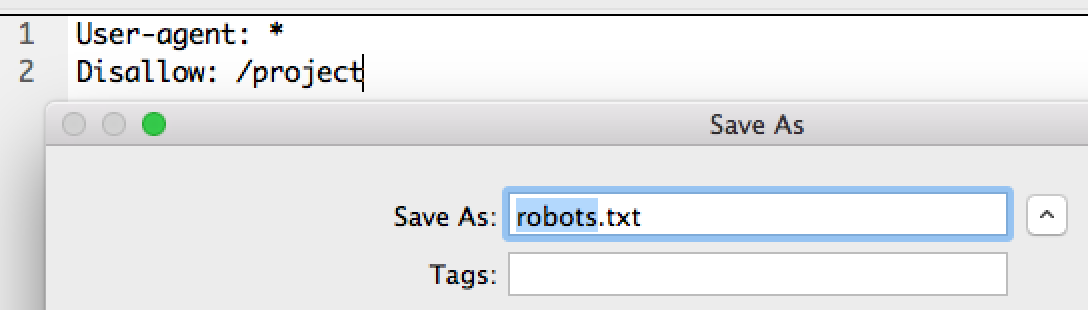
|
1
|
User-agent: *
|
|
1
|
User-agent: Googlebot
|
|
1
2
|
User-agent: *
Disallow: /
|
|
1
2
|
User-agent: *
Disallow:
|
|
1
2
3
4
|
User-agent: *
Disallow: /cgi-bin
Disallow: /project
Disallow: /email
|
วิธีตรวจสอบว่า robots.txt แล้วหรือยัง
หลังจากที่เราสร้างไฟล์ robots.txt และเขียนคำสั่งต่าง ๆ เรียบร้อยแล้ว เราจะเช็กได้โดยการ ใส่ https://www.your-domain.com/robots.txt เป็นต้น
ปล.SoGoodweb ของเราได้ลง robots.txt ใว้ให้โดยอัตโนมัติ
ขอบคุณแหล่งที่มา: codebee









